

My Family Tree ID System
My detailed relationship-based family tree numbering system; the story of how and why I made it years ago and how you could use today.
GENEALOGYMY SYSTEMS
M, of MeghaVenture
8/7/202512 min read
Last Updated: April 10th, 2026.
I made this family tree ID numbering system years ago, sometime around 2010, when I was doing a lot of genealogy and was trying out different systems and tools to track all of it.
Terminology Note: in both usage and definition the terms "great aunt/uncle" and "grand aunt/uncle" can be used to describe both different relationships or the same relationship. I personally, and many who do genealogy, prefer the clarity of matching the degree of a grandparent's generational title to their siblings. Meaning calling a grandparent's sibling a grand aunt/uncle, a great grandparents' sibling a great aunt/uncle, and a great great grandparents' sibling a great great aunt/uncle, and so on.
Why?
Why did I make this system?
Why did other systems not appeal to me?
Why do I like my system?
How
How my family tree ID system works
The Tiers and Hierarchy of IDs
Tiers
Relational Codes
Other
Contents:
Why?
Why did I make this system?
The final straw that drove me to creating this system, was a part of my tree where a William Wilson married the daughter of another William Wilson. She was also the granddaughter, grandniece, sister and cousin to several other William Wilsons, and in her lifetime she would also be the mother and aunt to a new generation of several more William Wilsons. Her son would be born the same year as one of her nephews (both William Wilson), and there would be about five young William Wilsons born within the same time as her son (all her nephews and cousins). Funnily, Poe (my favorite poet) has a poem named 'William Wilson', which I discovered shortly after this frustration.
When you have multiple people with the same name in the same generation, of the same family, all born a few years apart, how are you supposed to keep them all straight? Keeping the records straight is one issue, but at this point you can't even look someone up in most family tree systems since you can't reasonably be expected to remember the exact birth and death year or every member of your tree.
Why did other systems not appeal to me?
Some where similar but working the in the opposite direction (tracking descendants of a person instead of ancestors of a family group). Others were too random or vague or excluded siblings families who are often vital to finding documents for the overall line.
I wanted a system based on a sibling group (or a couple & their kids). I wanted a system that used ID's that told me information about the person (besides what order they were added to the system in). I also wanted a system that would allow me to cover extended family, in-laws, adoption and modern families so the system can continue to be used into the future.
Why do I like my system?
I know key information about someone by their ID number.
Files stored with the ID number short nicely* (keeping files for siblings and generations close together & well ordered).
I can quickly mentally turn a relationship into the ID of the person or calculate a parent, sibling, spouse or child of a person from their ID (or guess their surname).
It makes combining DNA with Genealogy easier as IDs alone can note biological relation and be used to track or identify Y-chromosome or mtDNA lines.
*Some file systems mess up multi digit numbers (instead of '1, 2, 3,...10, 11...' they go '1, 10, 11,... 2, 20, 21...'). Such file systems will be less ordered within generations if sub folders for families or direct ancestors are not used (and sibling groups of more than 9 will be improperly ordered even then).
How
How my family tree ID system works
My system is based on the direct ancestors of a target sibling group (or an only child). The ID's for individuals represents a relationship to either the target sibling group or one of their direct ancestors, rather than an actual person. While usually one person will have one relationship it is possible, both in real life and in my system, for someone to have multiple relationships and thus an ID for each.
The system has four types of IDs: all are either a two or three number ID with an additional 'relational code' that appends the ID when needed. These four types are in a hierarchy and each person must be assigned an ID in the highest tier possible for the given relationship.
The Tiers and Hierarchy of the IDs:
Target Group
The target group is the sibling group that the family tree is targeting (in some tools this is one person and is called the "home person"). The target group could be considered the 'Tier 0' for the system, but is not included in the tiers.
Each child in the target sibling group has an ID number of 0-# where 0 is the target group generation and # is the child's birth order number.
Tier Hierarchy:
Direct Ancestors: [generation number] - [Tier 1 order number (paternal to maternal)].
Siblings of Tier 1: [Sibling's Tier 1 ID] - [Tier 2 order number (birth order)].
Spouses: [Spouse's ID]s#.
Children: [Parent's ID]c#.
Tiers
Tier 1: Direct Ancestors
Pictures help, so here's a basic family tree, with the first four generations, and the ID for each person labeled with their relation.
In the image notice that all the codes are two numbers separated by a dash, and that the first number is the same for everyone in the same column. This is because the first number is the generation, and the second number identifies the person in that generation (either by birth order like the children in gen 0 or their vertical position in the generation like the other three generations).
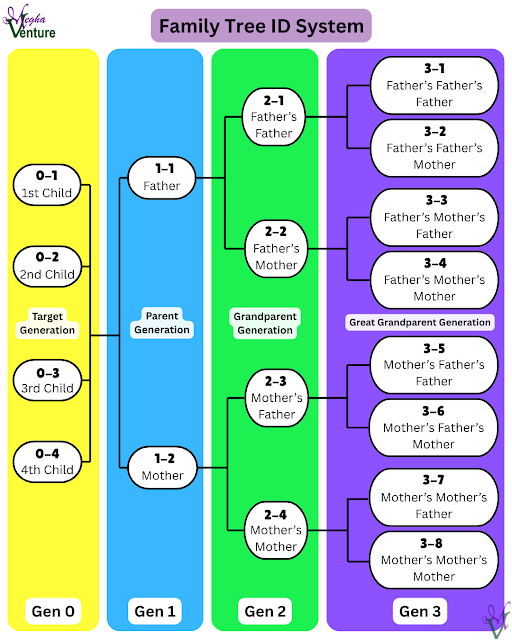
Detailed Image Description: The image shows four generations of a family tree. Each generation section has been given a color, a label, and a name. The first and leftmost generation is colored yellow, labeled "Gen 0" and named "Target Generation" it contains four siblings: the first child has the ID of "0-1", the second child has the ID of "0-2", the third child has the ID of "0-3", and the fourth child has the ID of "0-4". The second of the four generations is colored in blue, label "Gen 1" and named "Parent Generation". It contains only two people: the father (ID "1-1") and mother (ID "1-2") of four children in the last section. The third section is colored green, labeled "Gen 2", and named "Grandparents Generation". It contains the four grandparents of the four children in the first section: the father's father has the ID of "2-1", the father's mother has an ID of "2-2", the mother's father has the ID of "2-3" and the mother's mother has the ID of "2-4". In the last section is colored purple, labeled "Gen 3", and named "Great Grandparent Generation". It contains the eight great grandparents of the four children in the first section: the father's father's father (ID 3-1), the father's father's mother (ID 3-2), the father's mother's father (ID 3-3), the father's mother's mother (ID 3-4), the mother's father's father (ID 3-5), the mother's father's mother (ID 3-6), the mother's mother's father (ID 3-7) and the mother's mother's mother (ID 3-8).
Image Summary & Explanation
As the image shows, the "target generation" (yellow) is generation zero and each child in the target sibling group has an ID number of 0-# (with # being that child's birth order number). The parents generation is generation one, with 'Father' being ID 1-1 and 'Mother' being ID 1-2 (as they are the in the first generation and are ordered from paternal to maternal). The grandparent generation is generation number two and so they have IDs of 2-# (where # is their position when ordered from paternal to maternal, just like the parents generation and all further generations). The great grandparent generation is generation three with IDs of 3-#. This pattern continues on and on, for as far back as you want to go, despite further generations not being pictured.
Calculations of Tier 1 IDs
Direct Ancestor's Sex from Their ID
Since the Tier 1 order number (second number) is based on listing from paternal to maternal (and tier one is all direct ancestors), the number can be used to find that ancestor's sex. Paternal ancestors come first so they are odd, while their maternal partner comes next in the list (making them even).
This means a couple is always an odd numbered paternal ancestor and the following even numbered maternal ancestor. This means in the vast majority of cases men are odd and women are even.
Direct Ancestor's Spouse's ID
As mentioned above when finding a direct ancestor's sex, since direct ancestors are listed paternal to maternal, the paternal partner (man/husband/etc) in the couple will have an odd number and his wife (etc) will have an even number.
So as long as both are direct ancestors, you can add 1 to find the wife (etc), or subtract 1 to find the husband (etc).
However, if the spouse isn't also a direct ancestor they would have Tier 3 ID: being their spouse's ID plus the relational code s# (where # is the marriage count for the Tier 1 spouse).
Parents' IDs from Child's ID
For direct ancestors, you can calculate both parents' IDs from the child's ID (starting from a gen 1 child). This is done by adding 1 to the generation and by doubling the child's order number to get the mother's order number and then subtracting 1 for the father.
Example:
ID 1-1's
mother = 2-2
[(Gen 1) +1] - [(Order Number = 1) x2]
father = 2-1
[(Gen 1) +1] - [((Order Number = 1) x2) -1]
ID 4-6's parents
5-11 & 5-12
[4+1] - [(6x2)] = mother
[mother's order number] -1 = father
Tier 2: Siblings of Direct Ancestors
Siblings of direct ancestors use their Tier 1 sibling's ID and add their birth order as the order number. So for example, 2-1 (Paternal Grandpa)'s siblings use 2-1-#, 1-2 (Mother)'s siblings use 1-2-#, and 2-4 (Maternal Grandma)'s siblings use 2-4-#.
Tier 3 & 4: Spouses & Children
Both Tier 3 and Tier 4 require the used of a relational code, and can be used on any parent or spouse regardless of the tier of ID (as long as ID hierarchy has been obeyed).
The relational code for spouses is "s#" with the # being the marriage or relationship count for their partner. For children the relational code is "c#" with the # being the birth order for that parent (or the pair of parents if both are Tier 1).
This means that:
if Father was married once before the relationship that lead to the target siblings, that person would have the ID 1-1s1.
If 1-1s1 had a child (without Father at any time) the ID would be 1-1s1c1
if Mother & Father divorce and Mother remarried that new spouse would have the ID 1-2s2
If Mother's new spouse has a child (without Mother at any time) their ID is 1-2s2c1
If the oldest child (0-1) married, their spouse would be 0-1s1 and if they had a child their ID would be 0-1c1.
Relational codes
Real world family trees are messy. People remarry, families blend, there is adoption, fostering, surrogacy, sperm and egg donation and even cases of double cousins or incest. There are biological parents or children and then there are legal and social parents or children.
The people actually doing the parenting aren't always the biological or legal parent of a child, and family is more than DNA or law. People should be able to track all forms of family, not just biological, or legal and they shouldn't have to have separate family trees to do it.
To allow a tree to cover all descendants and all ancestors, and just all relationships in a tree (which makes breaking brick walls much easier), my system uses the relational code. While relational codes can get a bit long, like in the the picture below, I love them for their easy clarity and easy sorting in a list or file system.
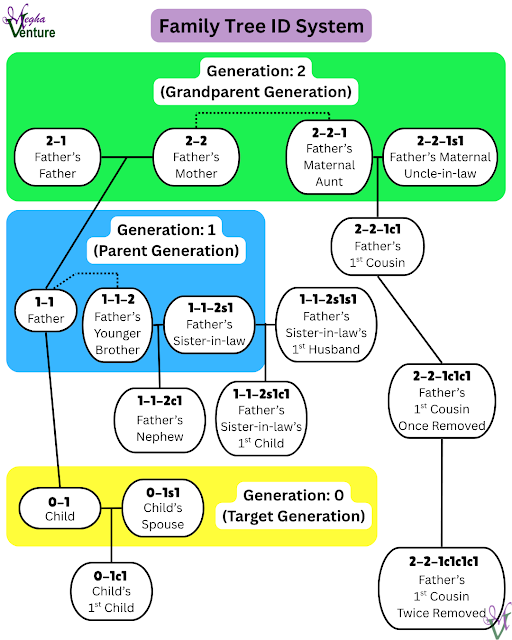
Image Summary & Explanation
As shown in the image, the IDs give a much clearer idea of relationship than traditional relationship titles. You can have tens or hundreds of first cousins twice removed but you will only possibly have one 2-2-1c1c1c1 and unlike the title the ID tells me the exact linage (from paternal grandmother's oldest sibling to their first child's first child's first child - compared to just "grandma's great niece or nephew").
The image also shows the difference between 1-1-2c1 & 1-1-2s1c1. While both children would be the father's nephew only one of them has DNA testing value (or medical history value) to the target group.
Types of Relational Codes
There are general relational codes that are always used in the system and are a part of Tier 3 and Tier 4 IDs (covered above). Then there are optional relational codes which can be used for extra information and additional family tree flexibility. Note that general relational codes are lowercase but optional relational codes are capitalized.
Relational Codes List:
These codes should all be appended to the end of an ID unless otherwise instructed.
"T" or "T#" = twin siblings or other multiple births
# = an optional count of multiple births in the family (some families have 2 or more)
"M" or "M#" = maternal half sibling
# = an optional count of the shared parent's children
"P" or "P#" = paternal half sibling
# = an optional count of the shared parent's children
"A" or "A#" = adoptive sibling OR parent ("a" can be used for a parent instead)
# = an optional count of adopted sibling groups in the family (order number before "A" should be their order in joining the family/household)
"MA#" or "M#A#" = maternally adopted sibling
"PA#" or "P#A#" = paternally adopted sibling
"F" or "F#" = foster sibling OR parent ("f" can be used for parents instead)
# = an optional count of fostered sibling groups in the family (for families who foster multiple children from different sibling groups)
"dM" or "dM#" = maternal donor half sibling
# = an optional count of donor's children
"dP" or "dP#" = paternal donor half sibling
# = an optional count of donor's children
"D" or "D#" = donor full sibling OR donor parent ("d" can be used for parents instead)
# = an optional count of the donor parents' shared children
"g" = gestating parent (for surrogate or birth but not biological parent)
Other Information:
The following is not necessary to understand my family tree ID system but could be very helpful for actually using the system.
Handling Modern Parenthood
Some cases (like gestating and donor parents) I have attempted to handle with relational codes, others I am still striving to address. Including the medical possibility of two eggs or two sperm making an embryo, or a mitochondrial DNA donor, or otherwise the medical use of a third person's DNA to create a child.
Types of IDs
Individual IDs
Everything we have covered so far, in this article, has been on individual IDs.
Family IDs
Each family in the tree has an ID based off of the pairing of parents (based on the parents' family tree IDs). Family IDs are written with the shortest & lowest parent ID listed first. Which is either the person with the highest ID tier (which is the same as the person with the closest relationship to the target group) or the "husband" for direct ancestor (T1) couples.
The dashes in the first parent's family tree ID are converted to periods, an "&" is added to the end, and then only the part of the other parent's ID that is different is added. Meaning for the family of 1-1 (Father) and 1-2 (Mother) the family ID is "1.1&2" and 0-1 (the oldest of the target children) and 0-1s3 (their third spouse) is "0.1&s3".
It is optional to separate the families of either parent with other spouses or to include all relationships either parent has in the same family ID. So if paternal grandpa remarried you could have 2.1&2 and 2.1&s1 or you could include grandpa's second wife (and any children) as part of 2.1&2 (I do this in my obsidian notes but not in file names).
Note: Records like census' that record a household should be saved with the family ID instead of all of the individuals on the record. If there are multiple families or if an unexpected relative is part of the household then the record should start with the shortest & lowest family ID, followed by all other IDs (shortest to lowest) whether family ID or individual. If there is not room for this then a "+" or "p" should be written to hold the place of any IDs that will not fit.
Tree IDs
When more than one tree is being kept, the family tree IDs should come after a family tree name, code, etc. This way records are not mixed up since the ID for each relationship (mother, father, etc.) doesn't change. For example, for a family tree with a mother "Jane Doe" and a father "John Smith" I would recommend a name like "Smith-Doe" ([father's surname]-[mother's maiden name]), or a code like "SD". Then individual IDs and family IDs would look something like "SD 1-2" for Mother or "Smith-Doe 1.1&2" for the family of Mother and Father.
Multiple IDs Per Person
In some situations, multiple IDs per person is ideal. It easily solves problems caused by incest or just two families inter-marrying. Siblings marrying siblings, isn't incest but still can cause the same type of family tree management or DNA relation tracking issues.
Multiple IDs should be ordered from lowest (generation & order number) to highest and then shortest to longest (as to list closest relationship first). Meaning that while 1-1-1c1 is longer than 2-1, it should still come first in a list as it is a closer relationship.
Multiple IDs is also very likely to happen when multiple trees are being tracked and intermarrying (or atleast interbreeding), like if someone has a tree for each of their parents and each of their partner's parents. The ordering should be the same (lowest to highest).
Order Numbers and Reality
While order numbers for Tier 2 IDs (or for a relational code) would ideally be in event order, in the real world that can be unrealistic. So in many cases this "order" would be more correctly defined as the order discovered or added to the tree.
I do personally believe an ideal family tree software would allow for reassigning an ID, and in that ideal case event order should always be used. I manage this in my person tree by using Obsidian notes for all Tier 1 and Tier 2 IDs (with all other relationships in the note of the closest relation) as a note's references in other notes is automatically updated when the note's name is changed.
What Goes After the ID in a File Names?
This is largely a matter of choice, and using my system the family tree ID or a family ID (or a list of individual IDs) is all that is needed. However, I use initials or a nickname to be able to identify siblings from memory as a sibling is easier to identify by family nickname or initials than their birth order, in most cases. I find this gives the most balance between information and filename length.